
The Washington Post investigated which websites got scraped to build up the database for Google’s chatbot. The Post has an online tool where you can check to see if your website was one of the ones that got scraped. And this online tool shows that danielharper.org was one of the websites that got scraped.
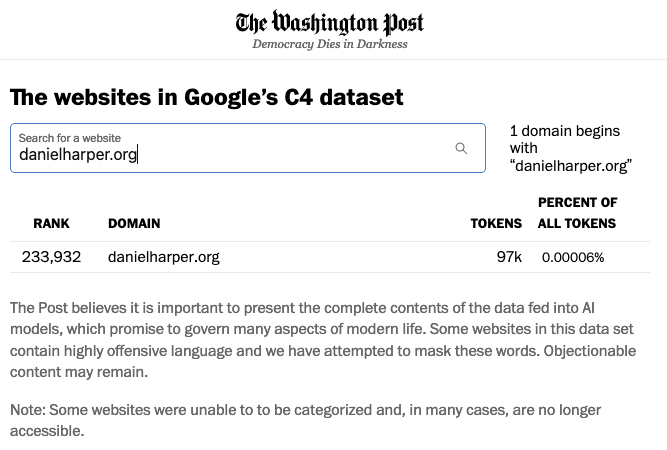
True, there were 233,931 websites that contributed more content than this one did. Nevertheless, I’m sure that Google will compensate me for the use of my copyright-protected material. So what if they used my material without my permission. Soon, a rep from Google will reach out to me, explaining why their scraping of my website is unlike those sleazy fly-by-night operations that steal copyright-protected material from the web to profit themselves without offering the least bit of compensation to the author. Not only will they pay me for the use of my material — they will also issue a written apology, and additional compensation because they forgot to ask permission before stealing, I mean using, my written work.
I heart Big Tech. They’re just so honest and ethical.